DocFlows
Reliably convert PDF documents into structured documents

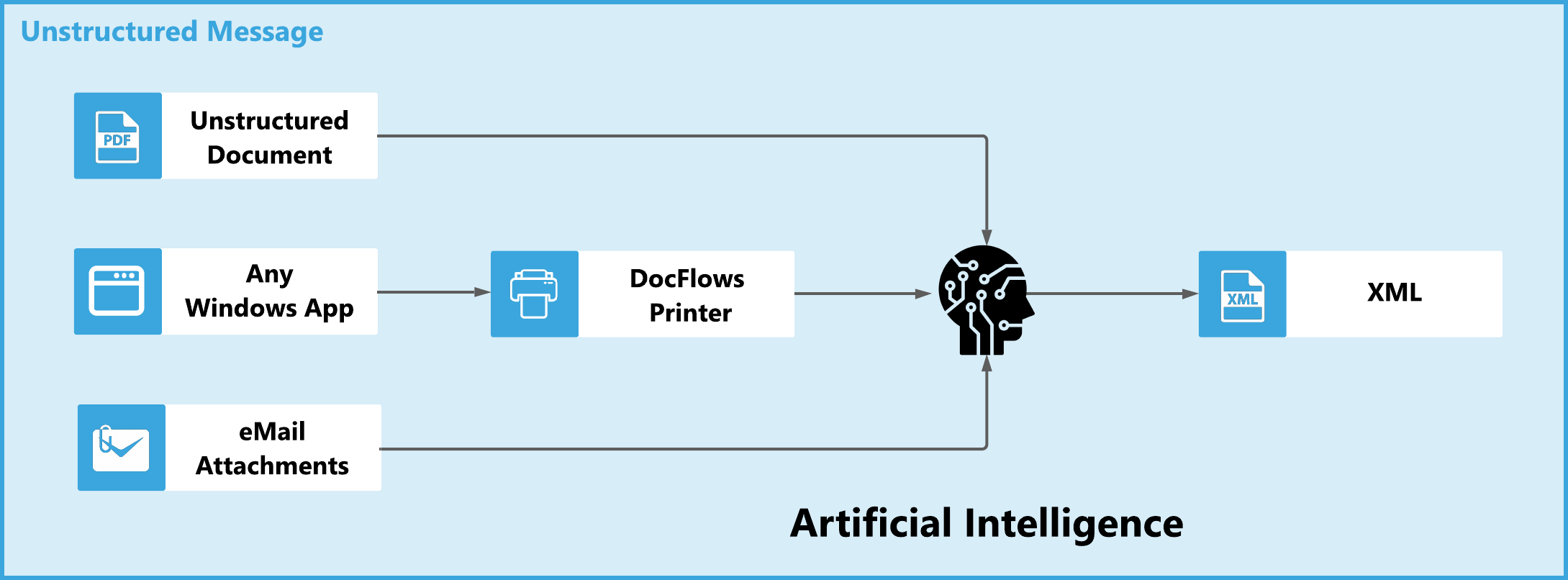
Many businesses still receive unstructured documents in their purchase-to-pay automation process. Documents, such as invoices, are printed out on paper and sent via regular postal services or sent as PDF attachments in e-mails.
Either way is not efficient because both structured and validated data are needed to import these documents into ERP-systems. So, these documents must be processed, converted to a structured version.
Today, most commonly used solutions rely on OCR-technology or pseudo manual retyping effort.
The first category is known for fast processing but tedious, inaccurate, and requires human intervention to create templates. By definition, Optical Character Recognition (OCR) is the technology that allows machines to scan printed or handwritten documents, PDFs, images taken by a camera, and convert image data into editable text formats automatically for further processing.
Current OCR systems provide a partial solution to some manual data capture issues, but they also create new ones. Human operators must write rules and templates for every invoice layout, making maintenance a never-ending task.
The second category, retyping, provides better overall accurate results, but the process is much slower because it requires human effort, it’s way more expensive than OCR, and it’s difficult to scale up because this requires additional trained staff.
Today D Soft introduces DocFlows, a new approach to solve the problem, a solution that combines the best of both worlds. It’s fast, scalable, affordable, and does not require any manual input from the customer. Unlike traditional OCR systems, DocFlows does not require templates.
Because the system is document-structure agnostic and relies on machine-learning technology, it delivers increasingly accurate results with continued use.
A few benefits
- Fast, scalable infrastructure
- Affordable
- Reliable
- Interoperable
Release info – Download our brochure (PDF EN) – www.docflows.eu
D Soft © 2022